Data Platform — Centralized ETL Infrastructure
Built a shared infrastructure platform that cut ETL pipeline onboarding from days of ad-hoc work to under two hours, then migrated twelve Python data pipelines off Supabase Edge Functions onto a centralised ECS cluster with a single reusable CI/CD workflow. All credentials were eliminated from source code. Any improvement to the platform — rollback logic, alerting, updated tooling — propagates to every pipeline on the next deploy.

Role: DevOps Engineer
Stack: AWS ECS Fargate · Terraform Modules · GitHub Actions (Reusable Workflows) · S3 · SSM Parameter Store · ECR
What Was Built
Designed and built a shared infrastructure platform that reduced new ETL pipeline onboarding from days of ad-hoc work to under two hours. Twelve data pipelines — each ingesting from a separate third-party API — were migrated from Supabase Edge Functions onto a single ECS cluster, a shared data lake, and one reusable CI/CD workflow. Credentials were eliminated from all source code and task definitions. Every pipeline now deploys through the same path, with the same security posture, maintained from one place.
The Challenge
The data engineering team ingests event and ticketing data from over a dozen third-party APIs — each one a separate Python ETL pipeline. When I joined, those pipelines were running as Supabase Edge Functions, which meant three Python engineers were maintaining TypeScript wrappers just to execute Python logic. Supabase Edge Functions also carry a 150-second execution timeout — a hard reliability risk for any ETL job hitting a slow external API or processing a large payload.
Beyond the runtime limitations, the deployment state was fragmented: some pipelines deployed manually, others used copy-pasted CI/CD workflows that had diverged in subtle ways, with credentials hardcoded in task definition JSON files and no consistent infrastructure pattern across them.
Adding a new pipeline meant either a developer spending days reverse-engineering an existing deployment, or a DevOps engineer writing bespoke Terraform from scratch. There was no shared cluster, no shared data lake, and no standard for how secrets, logging, or IAM permissions were handled. Fixing one pipeline's deployment setup had no effect on any of the others.
Why ECS Over Supabase Functions
Supabase's Pro tier costs $25/month and includes 2M function invocations — which sounds cost-efficient. But it's not a viable runtime for this workload. Edge Functions run on Deno (TypeScript/JavaScript only), have a 150-second execution ceiling, spin up cold on each invocation, and carry no persistent process state between runs.
Moving to ECS Fargate costs roughly $160/month for twelve always-on containers — about $135/month more. The tradeoff is clear: three Python engineers write Python instead of TypeScript wrappers. No execution timeout. Persistent processes that maintain connection pools and state across loop iterations. Full CloudWatch observability per container. IAM-scoped access to every downstream resource. At Supabase's Team tier ($599/month), ECS is the cheaper option.
Design: Three Layers
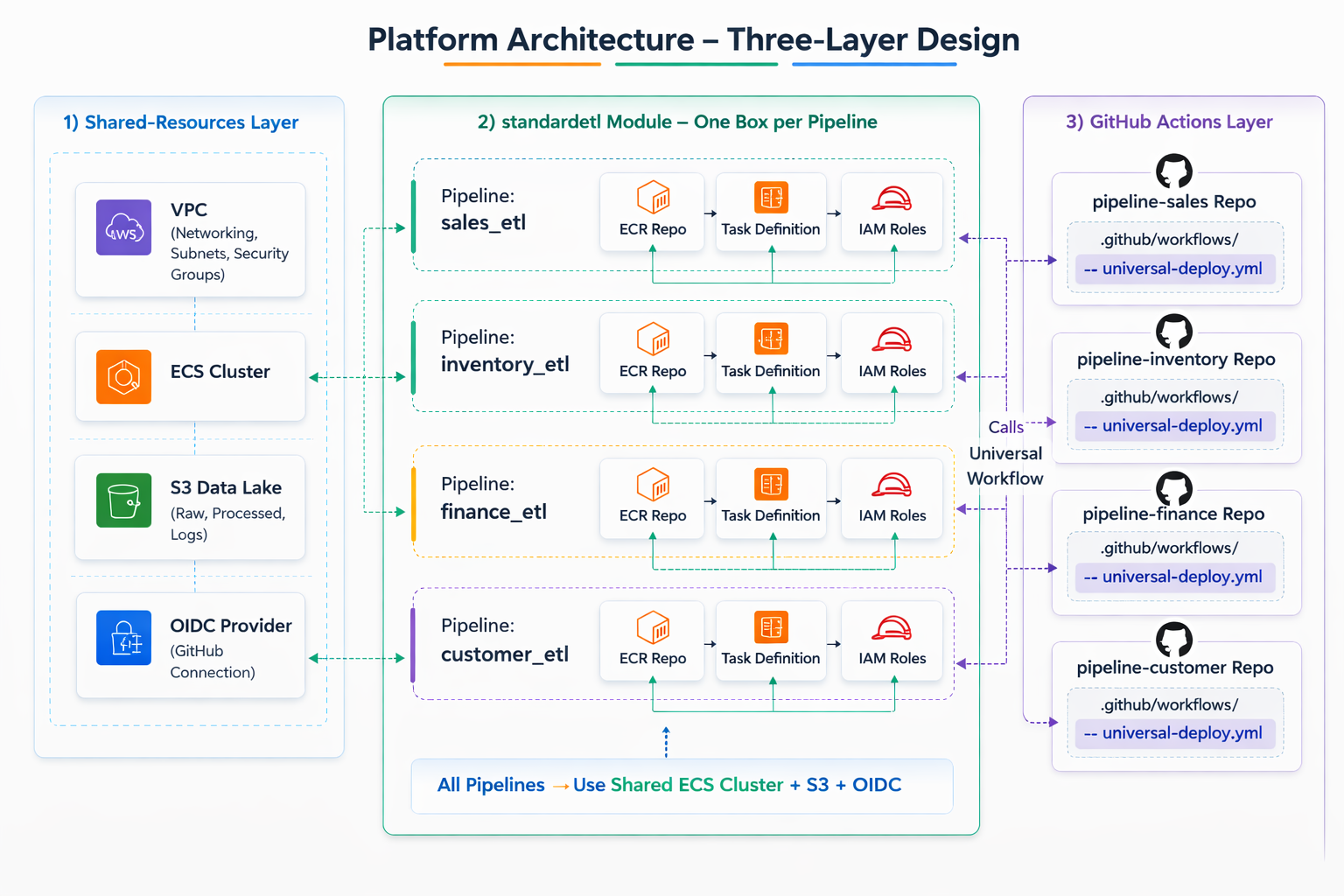
Layer 1: Shared Resources
A dedicated Terraform root provisions everything that pipelines share — applied once per environment:
- One VPC with subnets across two availability zones
- One ECS cluster where all pipeline containers run
- One S3 data lake bucket where all pipelines write their Parquet output
- One shared security group — outbound unrestricted to reach external APIs and AWS services, inbound blocked from the internet entirely
- One OIDC provider and a shared deployer IAM role — scoped to the organisation's GitHub repositories
The key leverage in that last point: OIDC is configured once. Every new pipeline repository gets deployment access automatically, without any additional IAM work. The shared stack outputs the networking IDs, cluster name, and deployer role ARN that pipeline modules consume as inputs.
Layer 2: The standard-etl Module
A Terraform module that provisions everything a single pipeline needs: ECR repository, ECS task definition, ECS service on the shared cluster, task execution role (to pull images and fetch secrets), task role (to write to the data lake), and a CloudWatch log group.
The module's interface is intentionally minimal. A new pipeline's entire infrastructure definition calls the module with a handful of inputs:
module "pipeline" {
source = "../../../modules/standard_etl"
app_name = "dp-[pipeline-name]"
env = "dev"
cluster_name = local.cluster_name
subnet_ids = local.subnet_ids
container_env = [
{ name = "ENVIRONMENT", value = "dev" },
{ name = "S3_BUCKET_NAME", value = local.data_lake_bucket },
{ name = "LOOP_INTERVAL", value = "3600" }
]
container_secrets = [
{ name = "API_KEY", valueFrom = local.api_key_ssm_arn },
{ name = "SLACK_WEBHOOK", valueFrom = local.slack_ssm_arn }
]
}
No secrets in Terraform. No credentials in the container definition. API keys live in SSM Parameter Store as SecureString values and are injected at container startup by the task execution role. The developer never sees them.
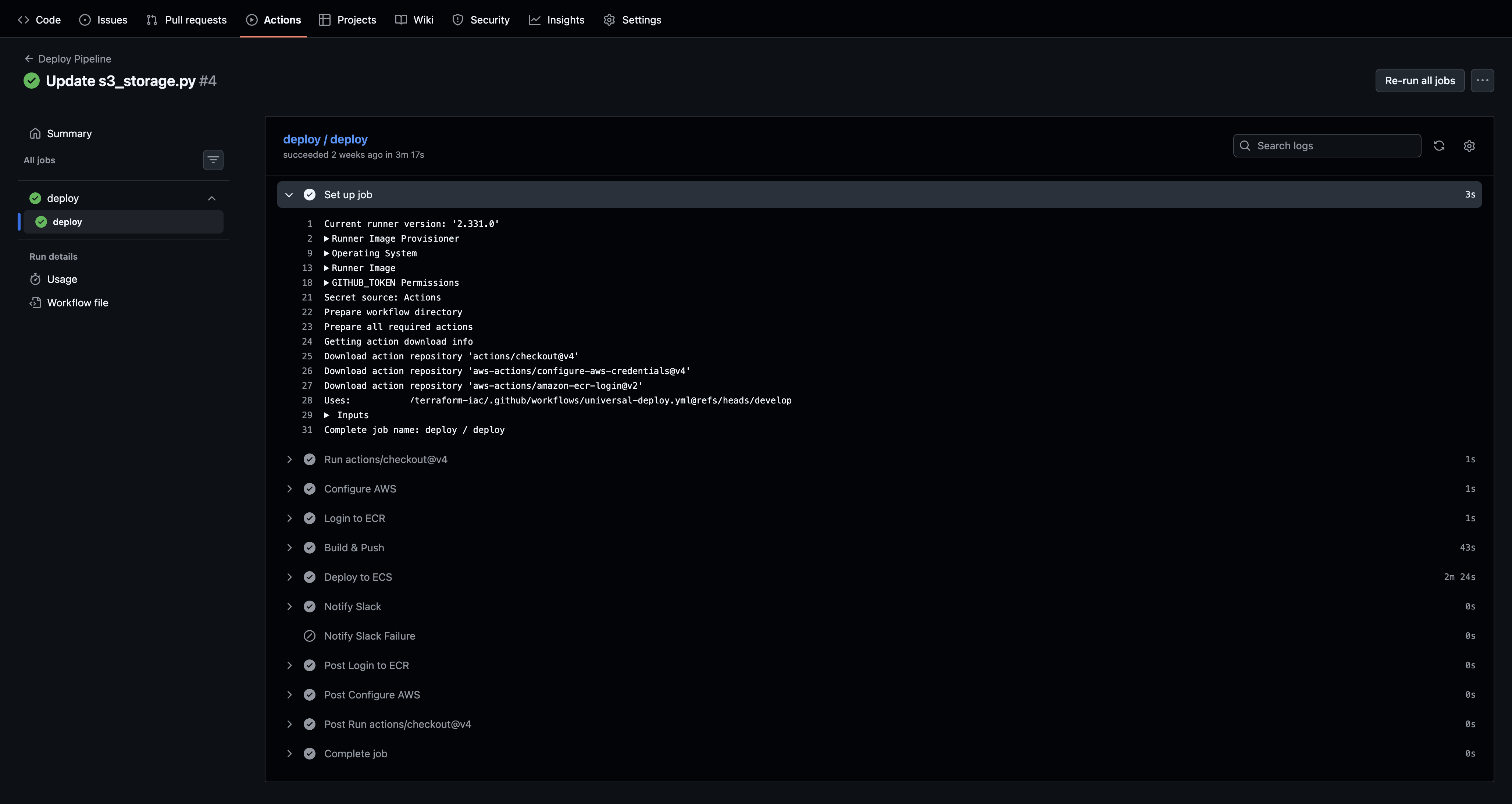
Layer 3: The Universal Deploy Workflow
The infrastructure repository hosts a reusable GitHub Actions workflow. Any pipeline repository deploys by calling it — not by writing its own CI/CD logic. The deploy.yml a developer adds to their repository passes the service name and inherits everything else:
jobs:
deploy:
uses: org/terraform-iac/.github/workflows/universal-deploy.yml@main
with:
service_name: "dp-[pipeline-name]"
secrets:
DEPLOY_ROLE_ARN: ${{ secrets.DEPLOY_ROLE_ARN }}
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
The central workflow handles OIDC authentication, container registry login, Docker build and push, task definition update, ECS service rollout, and Slack notification. If the workflow needs improvement — a rollback step, updated action versions, better error handling — it's fixed once and all pipelines inherit the change on their next deploy.
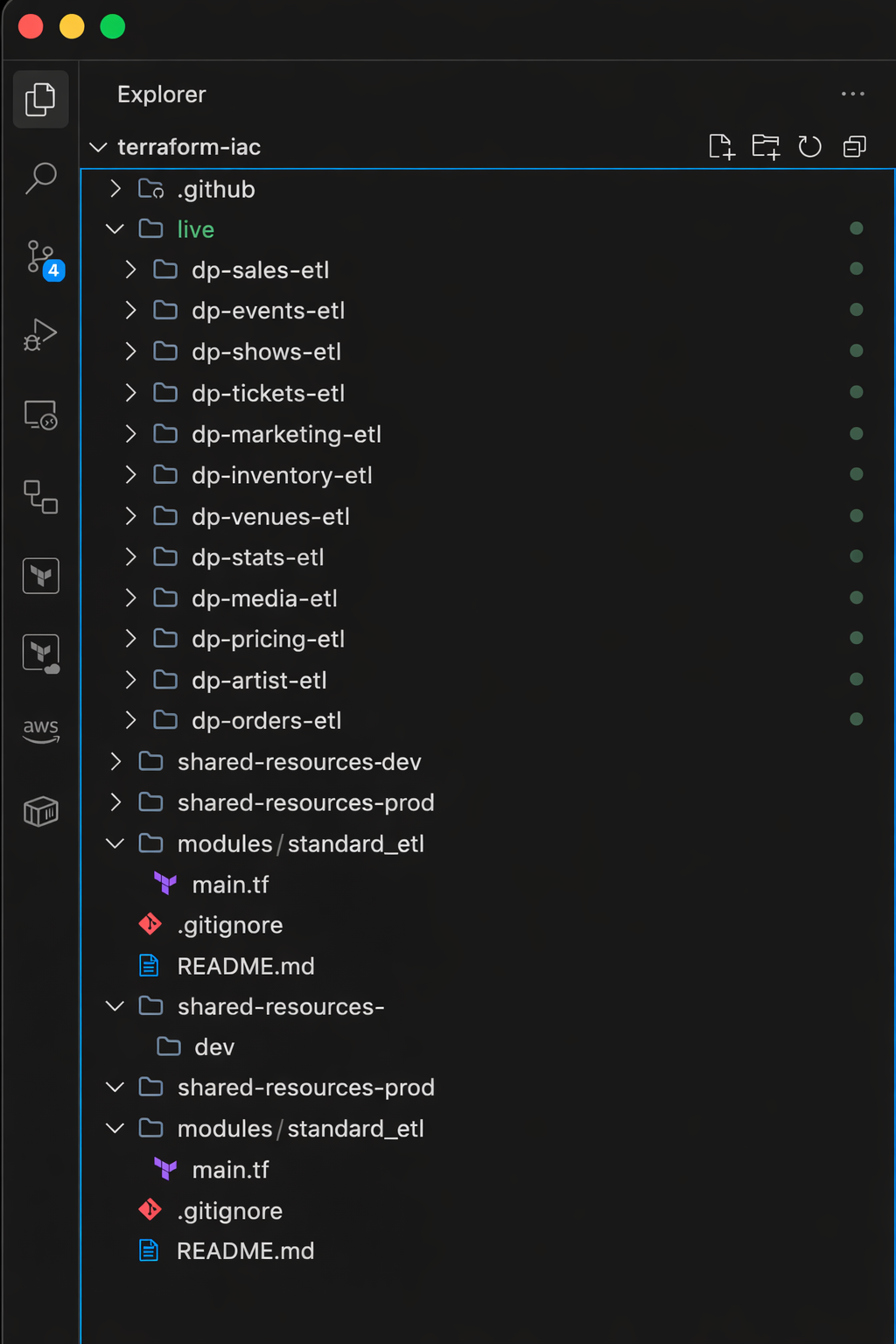
Migration
With the platform built, the existing pipelines were migrated one by one. For each:
- Secrets moved from hardcoded task definition JSON into SSM Parameter Store
- A
main.tfwritten callingstandard_etlwith the pipeline's specific inputs
terraform applyrun to provision resources on the shared cluster
- The old bespoke
deploy.ymlreplaced with the universal workflow call
- A push to the dev branch to confirm the new CI/CD path worked end-to-end
The first migration took the longest — that's where the module interface was refined based on real usage. By the end, each subsequent pipeline took under two hours to onboard, most of which was waiting for Terraform and the ECS service to stabilize.
Results
- 12 ETL pipelines running on the shared platform across dev and production.
- New pipeline onboarding reduced to under two hours — from days of ad-hoc work.
- Zero credentials in code or Terraform state. All secrets are in SSM and injected at runtime.
- One CI/CD workflow to maintain. Improvements apply to all pipelines simultaneously.
- Consistent operational posture across all pipelines — same logging, IAM boundaries, secrets pattern, and Slack alerting.
- Shared infrastructure efficiency. One cluster and one data lake serve the entire fleet, replacing per-pipeline resource sprawl.
Related reading: Building a Terraform Module That Teams Actually Reuse · Why I Put the CI/CD in the Infrastructure Repo